Background Information
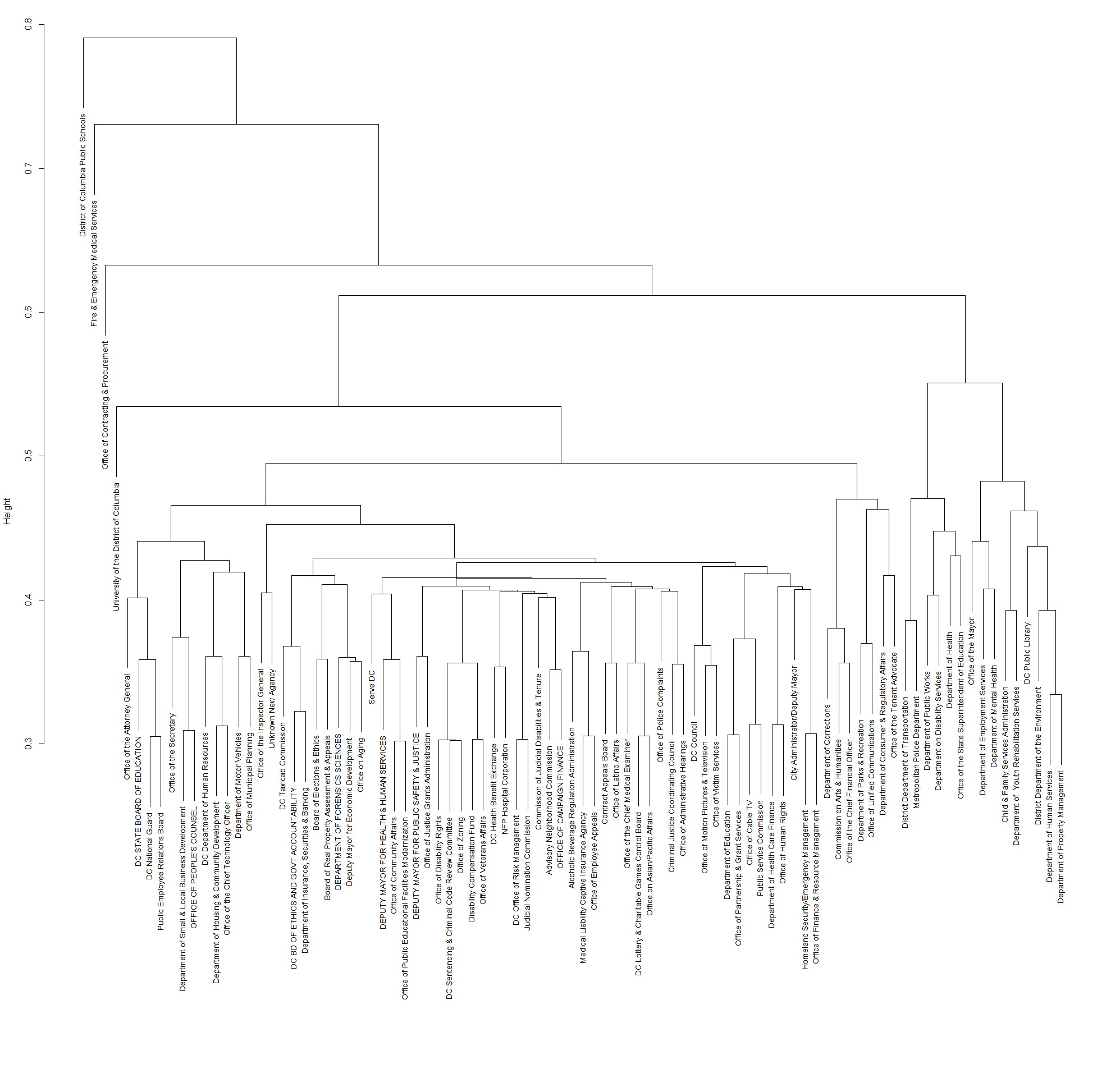
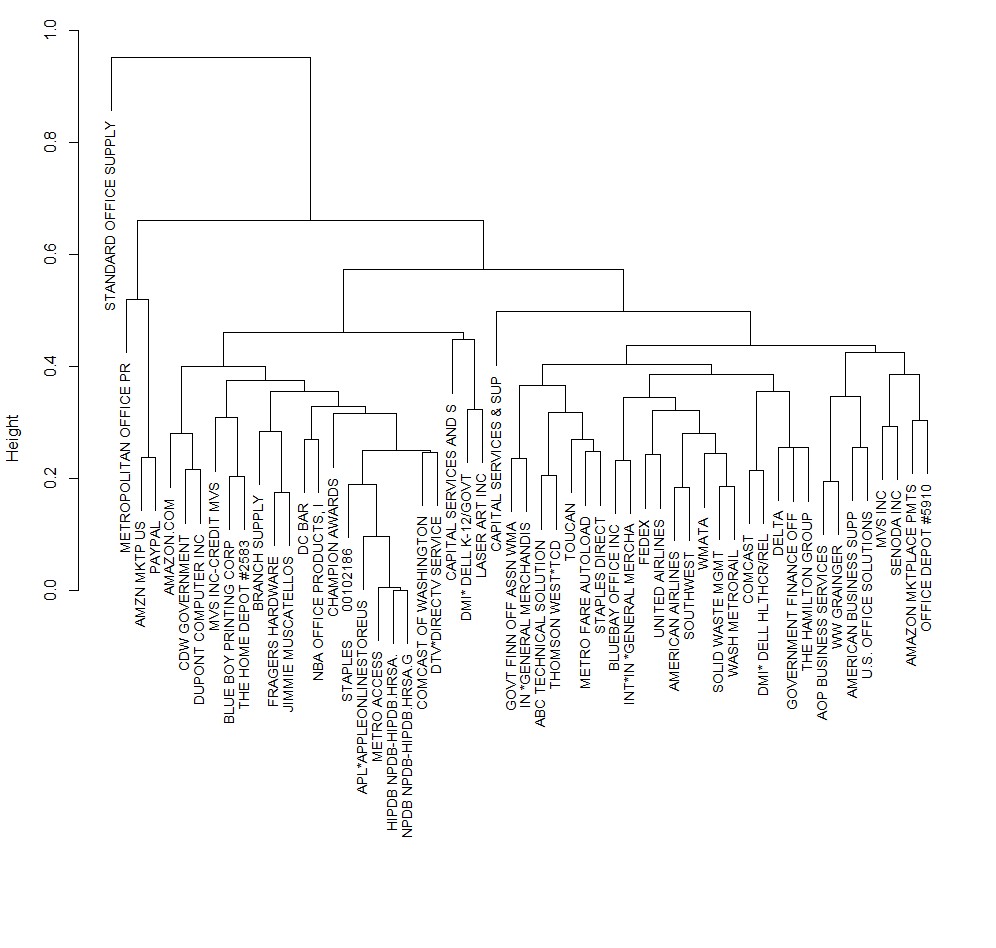
We were driven to start this project by the Bill.com Challenge in the Rice Datathon. For this challenge, we were given a data set with over 430,000 transactions made by government agencies in the Washington D.C. area. These purchases included information about which agency was making the transaction and for how much, what vendor they were making the transaction with, and it classified the vendor into various different categories of transactions. We wanted to understand the connectedness of the network by identifying similar businesses (or agencies) and similar vendors. We defined the metric for similarity using the top 5 most used vendors and top 3 most used categories (based on number of transactions), as well as the net total transaction value for each year. We also grouped the most used vendors together using the top 5 most transacted with agencies and the net total transaction value for each year.
We used this data and clustering techniques written in R to group the vendors and agencies together in clusters. After doing so, we looked at agencies in a cluster and the vendors that those clusters did business with the most and recommended those vendors to the businesses.
We believe that this information can be beneficial for both the agencies and the vendors. On the agencies side, this can be used to save the agencies, and as a result the taxpayer, money as they can more easily find vendors to do business within fields that they may need to business. On the vendors side, this can help businesses, especially small businesses, grow cliental and build their business through existing connections in the government.
Agency Findings
The dendrogram shown below shows all the agencies and their connections to each other ranked by the metrics laid out above, namely the top 5 most used vendors and top 3 most used categories based on the number of transactions, and the net total transaction value for each year.